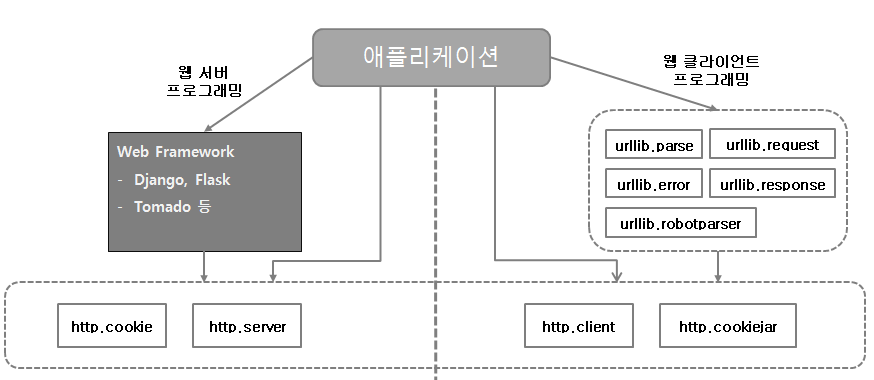
콩정의 개발 정리 블로그
콩정의 개발 정리 블로그
활용 API : 공공데이터포털
url 요청시 필수 파라미터 3가지
url요청시 필수 파라미터 3가지가 필요하다.
-
serviceKey
serviceKey번호는 공공데이터포털에 회원가입 후 고유 키 번호를 부여 받을 수 있다
-
stationId
-
routeId
내가 원하는 정류장 ID(stationid)와
노선번호(routeid)인 버스정보를 알아내기 위한 방법
[1] 경기버스정보에서 내가 찾고자하는 정류소를 입력 후
ex) http://www.gbis.go.kr/gbis2014/schBus.action?cmd=mainSearchText&searchText=만현10단지아이파크.현대성우5차
[2] 지도에서 해당 정류소 아이콘을 누르면
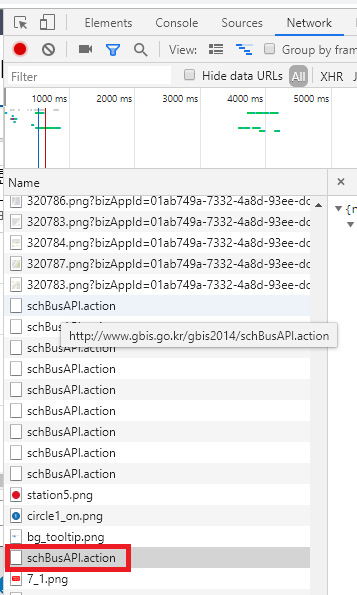
[3] 개발자모드 network tab의 schBusAPl.action에서 쉽게 찾을 수 있다
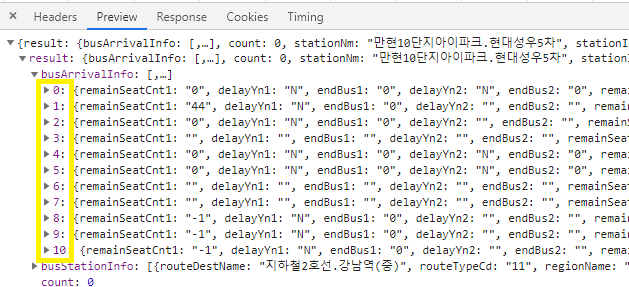
해당 정류소에 오는 버스 정보인
busArrivalInfo리스트가 보인다
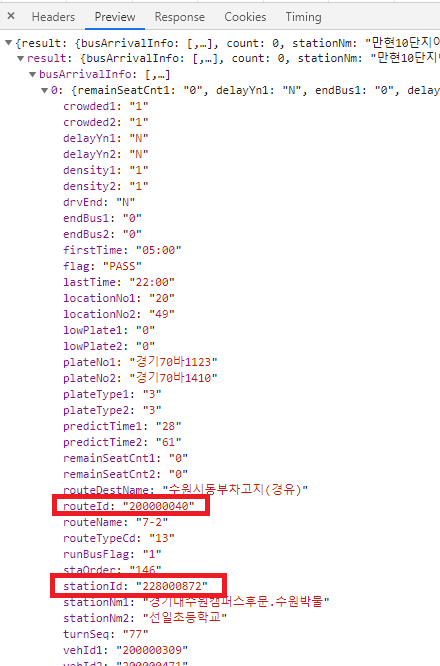
눌러보면
routeId와stationId를 확인 할 수 있다
포스트맨으로 실험하기
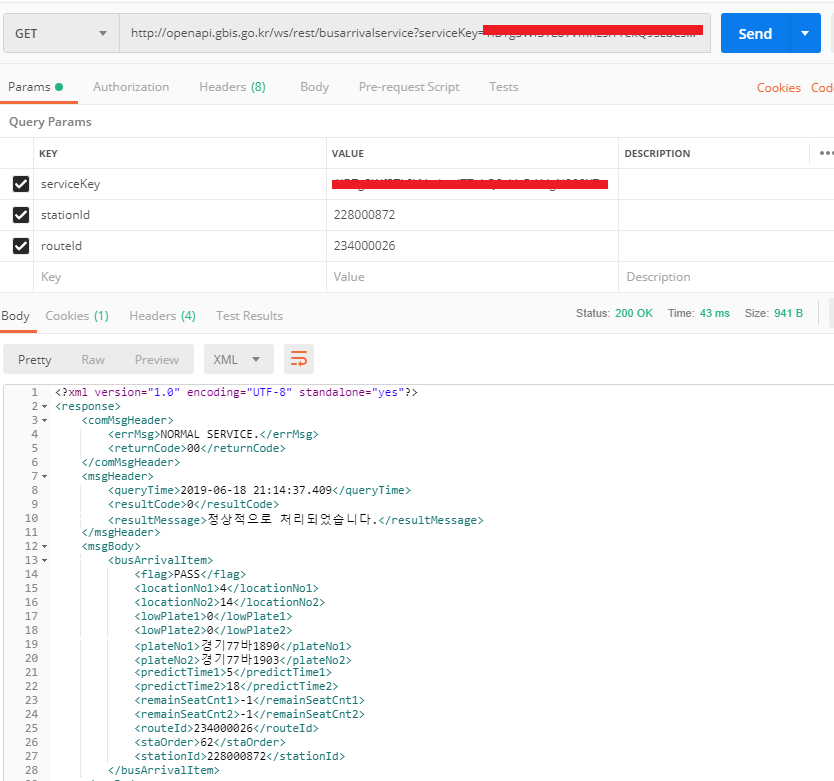
포스트맨으로 데이터를 보내면 원하는 값을 얻을 수 있다!
내가 가져오고 싶은 정보는, 버스의 도착 정보은
predictTime1이다!
1 - Test Code
텔레그램 챗봇 사용하는 법
챗봇에 적용하기 전 local에서 테스트 코드를 먼저 짜보았다..
크롤링이 처음이여서,
xml파싱을 하는 효율적인 코드를 잘 몰라 일단 html 파싱 방법과 동일하게 코드를 작성했다
def find_bus():
# 내가 원하는 버스 정류장에 오는 버스 정보를 dict 형태로 먼저 저장했다.
route_list = {
'234000026':'720-2',
'241420004':'82',
'241420009':'99',
'234000316':'60',
'200000040':'7-2',
'241420006':'82-1',
'234000027':'6900',
'234000046':'660',
'234000047':'720',
'234000136':'1550',
'234000148':'5500-2'
}
for routeId, busNo in route_list.items():
serviceKey = key값
stationId='228000872'
routeId=str(routeId)
url = "http://openapi.gbis.go.kr/ws/rest/busarrivalservice?serviceKey={}&stationId={}&routeId={}".format(serviceKey, stationId,routeId)
request = Request(url)
response = urlopen(request)
receive = response.read()
html = receive.decode('utf-8', errors='replace')
bs = BeautifulSoup(html, 'html.parser')
if bs.resultmessage.text == '정상적으로 처리되었습니다.':
print(busNo, ' : ', bs.predicttime1.text)
print(busNo, ' : ', bs.predicttime2.text)
if __name__ == '__main__':
find_bus()
720-2 : 3 720-2 : 15 60 : 12 60 : 29 7-2 : 51 7-2 : 91 660 : 42 660 : 127
잠시후 도착 버스와, 그 다음 버스 정보를 확인 할 수 있다!
2 - Telegram에 적용
AWS의 cloud9활용하여 telegram 챗봇을 이용하여, “버스”라는 단어를 입력하면,
바로 잠시 후 도착 정보를 보내주는 봇을 만들었다.
from flask import Flask, request, render_template
import requests
import time
import json
import os
from bs4 import BeautifulSoup as bs
app = Flask(__name__)
TELEGRAM_TOKEN = os.getenv('TELEGRAM_TOKEN')
API_TOKEN = os.getenv('API_TOKEN')
TELEGRAM_URL = 'https://api.hphk.io/telegram'
@app.route('/{}'.format(os.getenv('TELEGRAM_TOKEN')), methods=['POST'])
def telegram() :
# 텔레그램으로부터 요청이 들어 올 경우, 해당 요청을 처리하는 코드
#print(request.get_json()["message"]["from"]["id"])
#print(request.get_json()["message"]["text"])
response = request.get_json()
"""
response 데이터 확인하기
{'update_id': 693359414, 'message': {'message_id': 22, 'from': {'id': 748290634,
'is_bot': False, 'first_name': 'Jungjung', 'language_code': 'ko'}, 'chat': {'id': 748290634,
'first_name': 'Jungjung', 'type': 'private'}, 'date': 1545292109, 'text': '하이하이'}}
"""
chat_id = response["message"]["from"]["id"]
txt = response["message"]["text"]
if(txt == '안녕'):
msg = "존댓말."
elif txt == '버스':
route_list = {
'234000026':'720-2',
'241420004':'82',
'241420009':'99',
'234000316':'60',
'200000040':'7-2',
'241420006':'82-1',
'234000027':'6900',
'234000046':'660',
'234000047':'720',
'234000136':'1550',
'234000148':'5500-2'
}
results = []
for routeId, busNo in route_list.items():
serviceKey = API_TOKEN
stationId='228000872'
routeId=str(routeId)
url = "http://openapi.gbis.go.kr/ws/rest/busarrivalservice?serviceKey={}&stationId={}&routeId={}".format(serviceKey, stationId,routeId)
response = requests.get(url).text
bss = bs(response, 'html.parser')
if bss.resultmessage.text == '정상적으로 처리되었습니다.':
print(busNo, ' : ', bss.predicttime1.text)
print(busNo, ' : ', bss.predicttime2.text)
results.append([busNo, bss.predicttime1.text])
results.append([busNo, bss.predicttime2.text])
msg = ''
for i in results:
msg += '{} : {}분\n'.format(i[0], i[1])
elif(txt == '안녕하세요') :
msg = "넹"
# 네이버 환율 크롤링 코드
elif(txt == '환율') :
url = 'http://info.finance.naver.com/marketindex/exchangeList.nhn'
response = requests.get(url).text
soup = bs(response, 'html.parser')
soup = soup.find_all("td", {"class":{"tit", "sale"}})
exchanges={}
for i in range(88):
if(i == 0 or i % 2 == 0):
exchanges['국가'] = soup[i].text
elif(i % 2 == 1) :
exchanges['환율'] = soup[i].text
#print(exchanges)
#print(exchanges[0])
#print(exchanges[1]["cost"])
for i in range(len(exchanges)):
msg += ', '.join("{} = {}".format(key, val) for (key, val) in exchanges.items())
else:
msg = '등록되지 않은 메세지입니다.'
url = 'https://api.hphk.io/telegram/bot{}/sendMessage'.format(TELEGRAM_TOKEN)
requests.get(url, params = {"chat_id" : chat_id, "text" : msg})
return '', 200
@app.route('/set_webhook') # alert창 띄우기
def set_webhook():
url = TELEGRAM_URL + '/bot' + TELEGRAM_TOKEN + '/setWebhook'
params = {
'url' : 'https://sspy-week2-juneun.c9users.io/{}'.format(TELEGRAM_TOKEN)
}
response = requests.get(url, params = params).text
return response
결과 확인
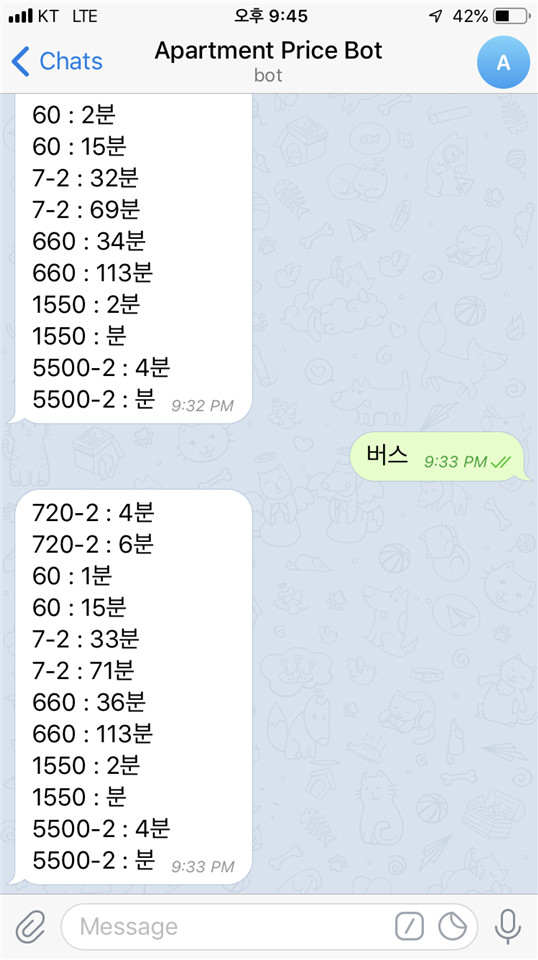
이제 아침에 급하게 뛰어나오면서 “버스”만 입력하면
잠시 후 도착 버스 정보를 확인할 수 있게 되었다 !